IP blocking is a technique made use of by sites to protect their internet sites from being scuffed. It is now clear that information scuffing is necessary to a business, whether it is for client purchase or company as well as profits growth. The product data discovered by a crawler will certainly then be downloaded and install-- this component ends up being web/data scratching. It might seem the very same, nevertheless, there are some crucial distinctions in between scraping vs. crawling. Both scratching and creeping go together in the whole procedure of data celebration, so usually, when one is done, the other follows.
- Modern internet browsers such as Firefox and Chrome support you in that task by a feature called "Evaluate Component", readily available through a right-click on the web page element.
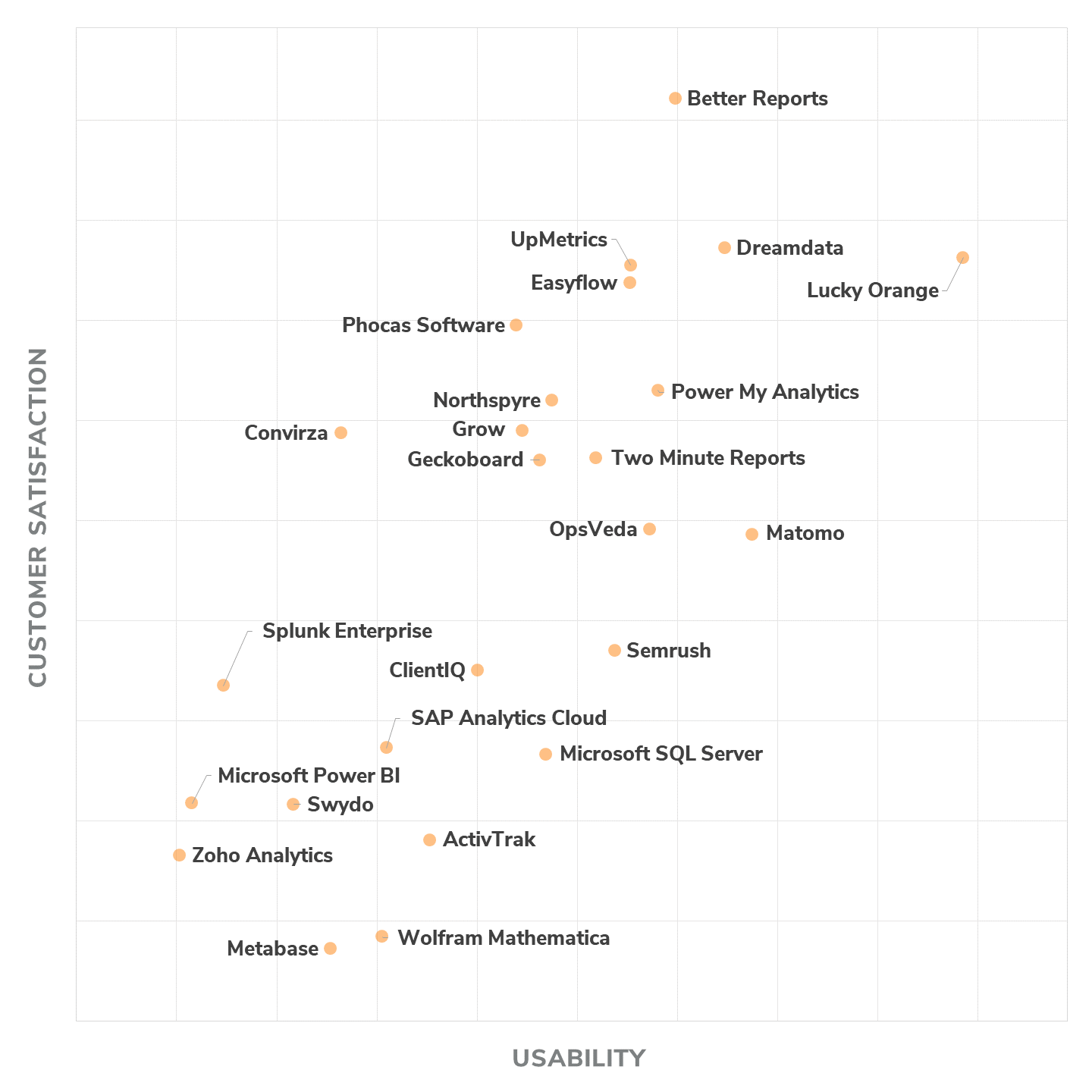
- Large renovations in information scuffing from pictures and video clips will have far-reaching effects for digital marketers.
- The whole point of a crawler is to detect and also pass through links to other web pages and also get hold of data from those pages too.
- They used a data enthusiast to get internet data required to gain understandings into customers and also trends and also focus on analytical options for their consumers.
- As soon as we have the HTML we can then parse it for the data we're interested in evaluating.
You could be asking yourself why you need to purposefully add bottlenecks to your jobs. This is because sites often tend to have anti-crawler systems that can detect and block your requests if they all carry out simultaneously. With node-crawler's rateLimit, time API Integrations voids can be included in between demands, to ensure that they do not execute at the very same time. Provide your crawlers an unreasonable benefit with Crawlee, our prominent library for developing reliable scrapes in Node.js.
Usages Cases For Internet Scratching
Abigail Jones Nowadays, big data has actually been extensively made use of in numerous areas like shopping internet sites, social networks, medical reforms as well as financial records. Although there are several data companies to supply different data sources, special demands are not normally considered by such organizations. People or business want more details like the particular price of the item or the call info of various web sites. That might be the ground of the internet site data scratching service. You could currently discover there are several web site data extraction devices readily available online like Import.io and Octoparse.
What is the difference in between information scratching and data creeping?
Information crawling is a more comprehensive procedure of methodically checking out and also indexing information resources, while data scratching is a much more specific procedure of removing targeted data from those resources. Both methods can be used with each other to remove information from sites, databases, or various other sources.
As they're not aware of the distinction, they commonly take out replicate details from a post that might have been plagiarised from a different source. Furthermore, crawlers assist in checking web links as well as validating HTML codes. Internet spiders additionally have other names such as automated indexers and also robots. On the various other hand, internet scuffing downloads web pages to draw out a specific collection of data for analysis purposes, as an example, item details, pricing details, SEO information, or any type of other information collections. But another crawling instance would be when you have one web site that you wish to remove information from - in this case you recognize the domain - however you do not have the web page URLs of that particular site.
Browserless Arrangement
The removal of the textual data and/or metadata from the HTML resource code is called Rub. When you've defined the tags in your script or scratching application, you'll wish to carry out the code. Every little thing that we discussed in the above area concerning how data scrapes job comes into play below. Now that we understand exactly how an information scrape functions let's recognize some preliminary steps that are needed before you attempt to scrape a site yourself.
Cross-platform normalization enables machine learning model ... - Nature.com
Cross-platform normalization enables machine learning model ....
Posted: Sat, 25 Feb 2023 08:00:00 GMT [source]
Web scuffing is basically removing data from internet sites in a computerized way. In this write-up, read an explanation of the distinctions in between internet scuffing as well as internet crawling. To remove the information, the information spider drills deep right into the Internet. To discover what's relevant to your mission, think of spiders or robots scavenging through the Internet.
Creating The Crawler
In the above paragraph, I pointed out these devices with corresponding links. I very advise you examine them out prior to diving right into the example. Once you have that, you want to determine the unique tags that are around the rate so you can make use of that in your information scraper. Some excellent tags would certainly be div tags with IDs or really details class names. There are now information scrapingAI on the marketplace that can utilize device learningto continue improving at acknowledging inputs which just humans have actually traditionally had the ability to translate-- like pictures. Feeding item information from your website to Google Buying as well as various other 3rd party vendors is an essential application of data scraping for e-commerce.
- There are little to big business giving these activities as a solution which is much less pricey and also extra details to your demands and also saves you lots of time.
- Node.js is well known for the performance and also speed it provides.
- We might state that information creeping's purpose is to deal with enormous data sets where one builds crawlers that crawl to the deepest website of a website.
- As you remain to scrape information, you will likely locate the exact same fundamental patterns occurring over and over.
Our bot right here specifies a Crawler class with a number of helper approaches and then continues by instantiating the course with our IMDb begin URL and calling its run() technique. For this, examine the URL patterns of the page as well as check into the resource code with the 'check element' performance of your web browser to discover suitable XPATH expressions. To make sure that we obtain the dynamically made HTML web content of the site, we pass the original resource code dowloaded from the link to our PhantomJS session initially, as well as the usage the provided source. Import.ioImport.io is a feature-rich data mining device collection that does much Web Scraping Services of the effort for you. " reports that can inform you of updates to defined websites-- ideal for thorough https://s3.us-east-005.backblazeb2.com/Web-Scraping/Web-Scraping-Services/api-integration-services/4-internet-creeping-versions-web-scratching-with-python41557.html competitor analysis.
Installing Our Nodejs Web Scrape
This is where web ETL Processes as well as information scraping applications been available in convenient. You can configure these scraping applications to go to sites as well as remove the content/data that you desire. The noticeable advantage of this is being able to get the exact data that you want conveniently and efficiently. Data scuffing is the process of utilizing an application to extract valuable info from a website. This will allow us to acquire big quantities of data from websites in a short amount of time.
https://maps.google.com/maps?saddr=545%20King%20St%20W%20Unit%20239%2C%20Toronto%2C%20ON%20M5V%201M1%2C%20Canada&daddr=2%20Bloor%20St%20W%2C%20Toronto%2C%20ON%20M4W%203E2%2C%20Canada&t=&z=15&ie=UTF8&iwloc=&output=embed
You do not need any kind of technical expertise to accomplish complex web scratching jobs. To put it merely, HTML parsing is primarily absorbing HTML code as well as extracting relevant information like the title of the web page, paragraphs in the page, headings in the page, web links, vibrant text, and so on. It's primarily an internet crawler that methodically searches the Internet, normally for the purpose of web indexing. You can have internet scrapes that are self-built, yet that requires advanced programs expertise. And in your web Scrape, if you desire more capability, then you need much more experience. On the various other hand, scrapes that can easily be downloaded and also run are previously established pre-built web scrapers however with some restrictions.
Scientists develop 'wildDISCO' method to detect tiny cancerous tumors - Interesting Engineering
Scientists develop 'wildDISCO' method to detect tiny cancerous tumors.
Posted: Tue, 11 Jul 2023 13:39:00 GMT [source]
What is the distinction in between scrapping as well as creeping?
Web scraping goals to remove the data on web pages, and internet crawling purposes to index and find web pages. Web crawling includes complying with web links permanently based upon links. In contrast, internet scuffing indicates composing a program computer that can stealthily collect data from numerous websites.